Every Value. Every Relationship.
Every Point in Time.
Most platforms forget. GroveStreams remembers — every value, every relationship, every change. One platform replaces your historian, your analytics engine, and your ML pipeline. Your AI agent queries it all with one language.
6,600+ organizations · 1.7M streams · 307K derivations · A decade in production
Imagine a data platform where every cell has its own time axis.
Imagine relationships that evolve — and derivations that automatically recalculate.
Imagine changing the past — and watching the future recalculate.
Imagine the complete temporal story of your data, one query away.
The temporal FK chains, the deep cells, the no-history-tables story aren't bound to meters and sensors. Here's the same diagram with an HR schema — employees, departments, offices — same pillars, same arrows, same architecture.
One Platform Instead of Eight Systems
Every temporal data project requires the same infrastructure. GroveStreams builds it all in.
| Instead of building… | GroveStreams gives you… |
|---|---|
| A separate historian for time-series storage | 100M+ points per stream with real-time rollups built in |
| History tables, triggers, and temporal schema on your relational database | TEQ™ — relational query semantics over temporal streams |
_history tables, SCD2 patterns, and change triggers for every entity |
Every attribute is a stream — history is automatic, not hand-built |
| Batch analytics pipelines for rollups and statistics | Live or scheduled derivations, plus dozens of pre-computed statistics per stream |
| A separate dashboard and reporting tool | Built-in visualization with ODBC/JDBC adapter (Beta) and OData export to Power BI, Tableau, and more — saved-query VIEWs expose full temporal history to BI tools |
| An ML team for time-series forecasting | 8 built-in forecasting models — configure or code, your choice |
| A separate geospatial database or bolt-on package for location tracking | Location is just another stream — track position over time with the same queries, rollups, and AI |
| A separate security layer per query path, per tool, per dashboard | Per-user RBAC inside the query engine — same dashboard, different data per user |
Replace Half Your Tables
Every organization builds the same scaffolding: _history tables, audit triggers, slowly changing dimension patterns, materialized views for rollups, junction tables with effective dates. That scaffolding typically doubles or triples your table count — and you rebuild it from scratch for every project.
Traditional: Employee Management
employeesemployee_salary_historyemployee_title_historyemployee_dept_historydept_transfer_auditheadcount_quarterly_mvcompensation_rollup_mv- Triggers to populate history
- Batch jobs for rollups
9 objects. Hand-built. Per project.
GroveStreams: Same Capability
employeetemplate with 5 streams:salary, title, departmentUid, managerUid, location
History is automatic. Rollups are automatic. Relationship tracking is automatic. Query any attribute at any point in time with a standard JOIN.
1 template. 5 streams. Done.
Simpler Schema. Smarter AI.
This isn't "we added an AI chatbot." The architecture itself is why AI works better here.
AI on a traditional schema
Your AI agent has to navigate 9+ tables per domain. It needs to understand your SCD2 conventions, your trigger logic, your materialized view refresh schedules, and your junction table naming patterns. It generates 15-line queries with CTEs, date math, and temporal joins. Get any of it wrong and the query silently returns bad data.
AI on GroveStreams
Your AI agent sees 1 template, 5 streams, and asks:
salary(range(sd=-1y), CycleId='quarterly', Stat='avg')
Fewer objects. Fewer joins. Fewer round-trips. Faster answers. The agent generates correct queries far more reliably because there's so much less to get wrong. And when it's time to build a new data model, the agent generates DDL — not a migration script across nine tables.
The simpler your data model, the more reliable — and faster — your AI becomes.
It's also why the GS SQL documentation is thorough enough to drop straight into an LLM's context window as a working reference. Read it yourself.
Platform Capabilities
Temporal Schemas
Most platforms only show you where things are today. GroveStreams remembers the complete history of every value, every relationship, and every hierarchy. Query how your data model evolved over time — not just your data.
- Temporal foreign keys across component hierarchies
- Track property changes over time, not just current values
- 100M+ data points per stream — three years of one-second data
- Live schema evolution — modify a template and reconciliation propagates to every linked component with zero downtime
- Entity diagrams — visual layout of templates, views, and the foreign-key relationships that connect them. Shared across users in the org, manageable via DDL (
PLACE NODE,PLACE VIEW,RELATIONSHIP)
GS SQL + AI Assistant
GS SQL extends standard SQL with temporal semantics — full DDL and CRUD, cycle-based aggregations, temporal JOINs, point-in-time queries via temporal parameters, and time-filtered statistics. The built-in AI assistant connects to OpenAI, Anthropic, Gemini, or xAI and executes GS SQL against your live data — from ad-hoc queries to building entire data models from a natural-language description.
- Full DDL & CRUD — CREATE, ALTER, DROP for 15+ entity types; INSERT, UPDATE, DELETE for components, streams, and data
- AI schema generation — describe a data model and the assistant builds templates, FKs, rollup calendars, and derived streams
- Dozens of real-time statistics per stream, computed as data arrives
- Temporal JOINs across component hierarchies
- Saved-query Views — promote any GS SQL query to a named view. Internal (your data) or external (live JDBC to PostgreSQL/MySQL/etc. via
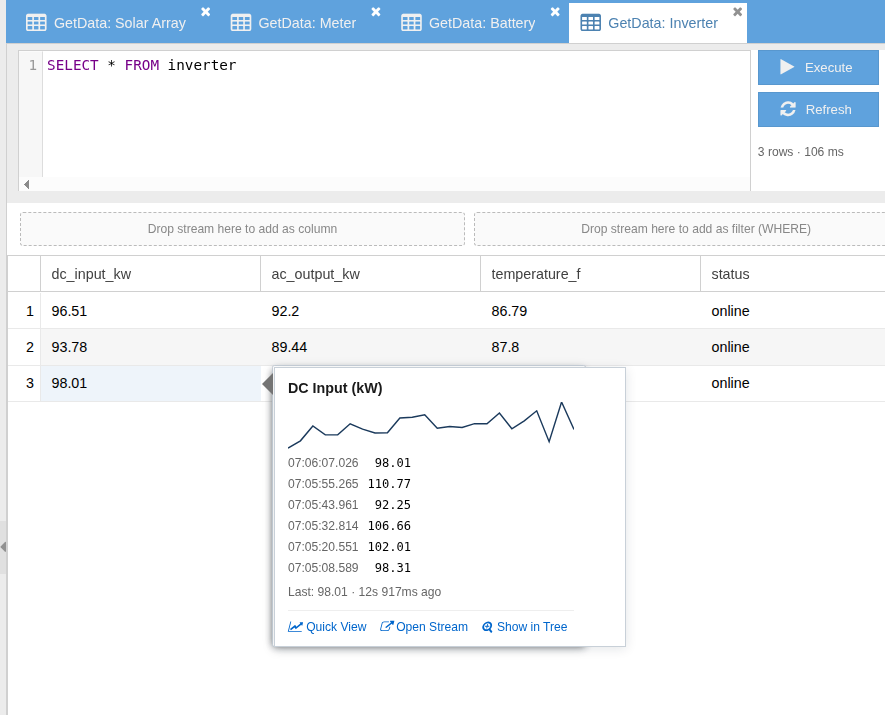
CREATE VIEW ... CONNECTION), materialized for caching or live on every reference. Views appear as tables in subsequent SQL and to BI tools via ODBC - GetData — drillable, editable results — every cell in a GS SQL result carries server-stamped origin metadata. Hover surfaces a sparkline plus a recent-samples grid; right-click drills into the stream's full history, diagnoses a derivation, or follows a foreign key; Set Value writes back to the underlying temporal stream at the original sample time (replace) or at "now" (append). See how it works →
- 8 AI forecasting models: TFT, NBEATS, ARIMA, Prophet, TCN, Transformer, ES, RNN
- AI correlation detection for covariates and leading indicators
- AI functions in SQL — call an LLM inline from any query:
agent_string,agent_boolean,agent_double/long, andagent_jsonclassify, score, and extract per row — and per derived-stream sample. Typed by function name, structured output from a template schema, and reads document and image file streams. Same RBAC and billing as the AI Assistant.
Real-Time Rollups & Derivations
Define rollup calendars that aggregate high-frequency data into any time hierarchy — seconds to minutes to hours to days to months to quarters to years. Calendars align to any reference point: midnight, shift start, billing cycle date, or each component's individual signup date. Model real-world time boundaries, not just clock boundaries.
- User-defined rollup hierarchies with configurable statistical functions
- Per-component reference dates — each entity's rollups align to its own lifecycle (e.g., billing cycles based on individual signup dates)
- Derived streams with formula expressions across any streams in your org
- Automatic dependency detection and chained derivation
- Retroactive change propagation — correct a historical value and all affected rollups, derivations, and FK-resolved calculations recalculate automatically
- FK-resolved dependencies — derivation automatically follows relationship changes over time, using the correct target entity's data for each period. Declarative DDL, automatic boundary detection. See how it works →
- Gap detection, time-of-use billing determinants, time-weighted averages
Connect Everything. See Everything.
Ingest via REST API with fine-grained API-key security. Visualize with drag-and-drop dashboards, maps, and real-time charts. Connect Power BI, Tableau, DBeaver, Grafana, and Excel directly via standard ODBC/JDBC drivers — or use the OData connector. Custom branding with branded subdomains available.
- REST API with fine-grained access control
- Drag-and-drop dashboards with embeddable widgets
- ODBC/JDBC adapter (Beta) — any PostgreSQL driver connects directly, no special setup. Saved queries appear as VIEWs, giving BI tools full time-series access
- OData connector for Power BI Report Builder, SAP, IBM Cognos
- Event detection with alerts via email, SMS, and HTTP webhooks
- Location tracking — latitude, longitude, elevation, and heading are streams, not a separate spatial subsystem. Map any entity's position over time and correlate it with any other stream
Same Dashboard. Different Data. Per User.
Role-based access control is enforced inside the query engine — not at an API gateway, not in application code. User A sees their 50 components. User B sees their 200. The AI assistant, the ODBC/JDBC connection from Tableau, the OData feed to Power BI, and every GS SQL query all respect the same per-user permissions automatically.
- Per-user RBAC enforced at the query layer — unauthorized data is absent from results, not just hidden in the UI
- Security-aware dashboards — same URL, same layout, different data per user
- Your team configures access policies — no vendor dependency for day-to-day security management
- Consistent across every path: GS SQL, REST API, ODBC/JDBC, OData, AI assistant, dashboards
- SOC2-certified data center, SSL/TLS, 2FA, fine-grained API-key security
Your Team Runs It. We're Never on Your Critical Path.
GroveStreams is designed so your analysts can query it on day one — no specialized consultants, no onsite engagement, no six-figure implementation project. The AI assistant generates GS SQL from plain English, so your team doesn't need SQL experience to get started.
- We help you get started, but we don't have to live there — your team owns it day-to-day
- AI assistant translates natural language to GS SQL queries
- Drag-and-drop dashboards, point-and-click template design, formula editor
- Visual tools for analysts, full API for engineers — both paths to production
The Deep Cell Model
The architectural insight behind temporal intelligence — every cell carries its own time axis.
Visualize GroveStreams as a relational table where each entity is a row and each stream is a column — but every cell holds up to 100 million timestamped values, not just one. The current value sits on top. The complete history lives underneath.
This is what makes temporal intelligence possible: any query can reach any point in time. You don't pre-aggregate. You don't choose in advance which time ranges to keep. Every value, every relationship, every change — queryable with standard SQL, from one second to one decade.
Time-series databases store deep history but have no relational model — no JOINs across entities. Traditional databases have relational structure but each cell holds one value — temporal history requires separate history tables, triggers, and batch jobs. TimescaleDB and similar extensions add deep time-series storage to a relational model, but at the row level — rows are time-stamped, not cells. Historians store millions of points per tag but have no entity model at all. GroveStreams is the only platform we know of where every cell in a relational table is itself a complete time-series — and where the relationships between entities are themselves time-series too.
Relationships are deep cells too. When Pump-A is reconnected from Tank-7 to Tank-12, a new data point is appended to the relationship cell. The old connection stays in history. Query which pump fed which tank at any point in time — with a standard JOIN.
Location is a deep cell. Latitude, longitude, elevation, and heading are streams — not a separate spatial layer. A vehicle's position at 2pm last Tuesday lives in the same architecture as its fuel level, its assigned driver, and its maintenance schedule. Correlate location with any other stream using the same query language.
Read the full architecture story →| Entity | kwh | voltage | lat | customerUid |
|---|---|---|---|---|
| Meter-001 | 42.741.2 → 42.7 → ... | 121.3120.8 → 121.3 → ... | 44.9844.98 | cust-Acust-B → cust-A |
| Meter-002 | 18.417.9 → 18.4 → ... | 119.7120.1 → 119.7 → ... | 33.7540.71 → 33.75 | cust-Ccust-C |
| Meter-003 | 71.268.5 → 71.2 → ... | 122.0121.6 → 122.0 → ... | 41.8841.88 | cust-Acust-D → cust-A |
Each cell holds its full temporal history — current value on top, history below.
Same architecture, any domain:
| Entity | salary | title | departmentUid | managerUid |
|---|---|---|---|---|
| Emp-4201 | 145,000128,000 → 135,000 → 145,000 | Sr. EngineerEngineer → Sr. Engineer | dept-Engdept-Ops → dept-Eng | emp-3110emp-2900 → emp-3110 |
| Emp-4202 | 92,00085,000 → 92,000 | AnalystIntern → Analyst | dept-Findept-Fin | emp-3205emp-3140 → emp-3205 |
| Emp-4203 | 210,000175,000 → 195,000 → 210,000 | VP SalesDir. Sales → VP Sales | dept-Salesdept-Mktg → dept-Sales | emp-1001emp-2010 → emp-1001 |
Salary changes, title promotions, department transfers, reporting changes — all temporal, all queryable.
Temporal Relationships
The key differentiator: relationships are streams too.
When Pump-A is reconnected from Tank-7 to Tank-12, most platforms overwrite the pointer. GroveStreams appends a new data point to a link stream. The old connection stays in history.
Query which pump fed which tank on any date — with a standard JOIN. No junction tables. No history triggers. No audit logs. One stream.
├ 2024-01-15 → Tank-7
├ 2024-06-01 → Tank-12
└ 2025-02-10 → Tank-7
Derivation Follows Relationships Through Time
This is where temporal relationships become powerful. When a derived stream depends on a related entity's data, GroveStreams automatically detects when the relationship changed, splits the calculation into segments, and uses the correct target entity for each time period.
If a meter was connected to Customer A from January through June, then moved to Customer B in July, a cost derivation over the full year automatically uses Customer A's rate for Jan–Jun and Customer B's rate for Jul–Dec. Multi-hop chains (meter → customer → supplier) work the same way.
We're not aware of another platform that does this declaratively — not the time-series databases, stream processors, cloud data warehouses, or traditional relational databases we've evaluated. On those platforms, handling relationship changes during a calculation requires custom pipeline code. In GroveStreams, it's a single SQL expression on the variable definition.
See How It Works →Three API Layers
Ingest with TW. Query system internals with TDQ™. Query your semantic model with TEQ™.
Temporal Wire
Real-time signal ingestion via HTTP REST. The native ingestion layer for devices, APIs, and connectors.
Developer Docs →Temporal Deep Query
The core system layer — all internals exposed. Query the Stream table with the full power of the Sample column for reporting, dashboarding, and analytics.
GS SQL Overview →Temporal Entity Query
Query your semantic model with standard SQL. Template IDs as tables, stream IDs as columns, components as rows. FK JOINs between templates.
TEQ Guide →Built for AI Agents
Imagine an AI agent that can query 100 million data points per cell with temporal parameters that collapse complex time-series operations into a single line — and build entire data models from a natural-language description using DDL. That's what GroveStreams gives every agent.
The problem: traditional SQL for time-series
Ask a traditional database for "daily kWh totals per meter for the last 7 days, joined to the customer's region." This is what you get — CTEs, date math, GROUP BY on truncated timestamps, explicit JOINs to a separate customer table. An AI agent must generate all of this correctly, or the query fails.
-- Traditional SQL: 15+ lines, multiple failure points for an LLM
WITH date_range AS (
SELECT generate_series(
CURRENT_DATE - INTERVAL '7 days',
CURRENT_DATE,
INTERVAL '1 day'
) AS day
),
daily_kwh AS (
SELECT
m.meter_id,
DATE_TRUNC('day', r.reading_time) AS day,
SUM(r.kwh) AS daily_total
FROM meter_readings r
JOIN meters m ON r.meter_id = m.id
WHERE r.reading_time >= CURRENT_DATE - INTERVAL '7 days'
GROUP BY m.meter_id, DATE_TRUNC('day', r.reading_time)
)
SELECT d.meter_id, d.day, d.daily_total, c.region
FROM daily_kwh d
JOIN meter_customers mc ON d.meter_id = mc.meter_id
AND mc.effective_date <= d.day
AND (mc.end_date IS NULL OR mc.end_date > d.day)
JOIN customers c ON mc.customer_id = c.id
ORDER BY d.meter_id, d.dayThe same query in GS SQL™ (TEQ™)
The same question. Temporal parameters handle the date range, rollup, and aggregation. The temporal foreign key JOIN resolves which customer each meter belonged to at each point in time — automatically. With so little surface area to get wrong, an AI agent generates this reliably.
-- GS SQL: 4 lines. Same answer. No date math. No CTEs. No SCD2 joins.
SELECT m.cname, m.kwh(range(sd=-7d), CycleId='daily', Stat='sum'), c.region
FROM meter m
INNER JOIN customer c ON m.customerUid = c.cuid
ORDER BY m.cnameWhy this matters for AI
Hand-written SQL is one of the most common sources of LLM hallucinations in data applications. Date arithmetic, window functions, CTEs, SCD2 temporal joins — each is a failure point where the model generates plausible but broken syntax. GS SQL collapses most of them into declarative parameters. Temporal parameters (sd, CycleId, Stat, TimeFilterId) collapse complex time-series operations into declarative hints on the column. The platform does the rest.
When an AI agent hears "average temperature last week, rolled up hourly" — it maps directly:
SELECT cname, time, sample(range(sd=-7d), CycleId='hourly', Stat='avg')
FROM STREAM
WHERE id = 'temperature'No date arithmetic to get wrong. No window functions to hallucinate. No CTEs to nest incorrectly. The query is short enough for an AI agent to generate reliably, and deterministic enough for a human to verify at a glance.
More examples: temporal parameters in action
Peak-hours-only filtering, running totals, lag/lead window operations — all expressed as parameters, not code.
-- Last 30 days, hourly averages, peak hours only
SELECT cname, AVG(sample(range(sd=-30d), CycleId='hourly', Stat='avg', TimeFilterId='peak')) FROM STREAM
WHERE cname LIKE 'Meter%' AND id = 'kwh'
GROUP BY cname
-- Running kWh total for the current month
SELECT cname, kwh(running='sum', range(currentCycle='month')) FROM meter
-- Previous day's temperature (lag window parameter)
SELECT cname, temperature(lag=1, CycleId='daily', range(sd=-30d)) FROM sensorBring your own agent — MCP Server (Beta)
When you'd rather use Claude Desktop, Claude Code, Cursor, or any
Model Context Protocol
client, GroveStreams exposes a built-in MCP server. The agent gets four tools — describe_org,
run_gsql, ask_grovestreams, send_samples
— plus read-only Resources for help docs, templates, dashboards, and saved queries.
Authentication is per-user via OAuth 2.1 + PKCE so the agent runs under your RBAC, not a shared service account.
ODBC for your app, MCP for your AI.
Up and Running in Hours, Not Months
Vibe design your entire organization — entities, events, and dashboards — by describing what you need in natural language. The AI assistant builds the schema, the alerts, and the visualizations for you.
Connect
Point your devices at our REST API. Or pull from an existing PostgreSQL, MySQL, SQL Server, BigQuery, Snowflake, or Redshift database with the JDBC Import Wizard — it walks you through table selection, FK detection, and templating, then schedules incremental syncs. Components and streams register themselves automatically.
Vibe Design
Vibe design your organization — entities, events, dashboards, temporal schemas, rollup calendars, and derivation formulas — through the studio interface, GS SQL DDL, or the AI assistant. Describe what you need in natural language and it builds it for you. No data modelers, no dashboard developers, no alert engineers required.
Analyze
Query with GS SQL. Forecast with AI. Visualize in dashboards. Connect your BI tools directly via ODBC/JDBC or OData — saved queries appear as VIEWs so Tableau, Power BI, and Excel can access full temporal history, not just current values. Ask your AI assistant anything about your data.
"Why Not Just Bolt It Together?"
Fair question. A determined team could assemble InfluxDB + TimescaleDB + dbt + an LLM SQL layer and approximate some of this. Here's what you'd still be missing:
- Temporal relationships. No combination of off-the-shelf tools gives you link streams — relationships that are themselves time-series with full history. You'd build that from scratch.
- Automatic rollups across every stream. Not a dbt job you schedule. Real-time, as data arrives, at every level of your calendar hierarchy. Per-component reference dates included.
- FK-resolved derivations. When a formula depends on a related entity and that relationship changes mid-period, GroveStreams automatically splits the calculation and uses the correct target for each time segment. Try implementing that in dbt.
- One security model. Your bolted-together stack has a different access control surface per tool. GroveStreams enforces per-user RBAC at the query layer — same policy across SQL, API, ODBC/JDBC, OData, dashboards, and the AI assistant.
- One query language for the AI agent. Your LLM now needs to generate correct syntax for InfluxQL and PostgreSQL and your dbt model naming conventions and your custom API. Or it learns GS SQL — one dialect, one schema, one set of temporal parameters.
You can build it. The question is whether you want to maintain it — and whether your AI agent can reliably query it. Read the GS SQL docs and decide for yourself.
Comparing against a named platform? See our Cognite Data Fusion and AVEVA PI comparisons, the full Compare hub, or our roundup of the 10 best industrial intelligence platforms for 2026.
Change the Past. The Future Recalculates.
Think of GroveStreams as a temporal spreadsheet. In Excel, change a cell and every formula that references it recalculates. GroveStreams works the same way — except the cells go 100 million rows deep in time, and the formulas follow relationships that themselves change over time.
A meter reading from last month turns out to be wrong. A relationship changed and nobody recorded it until now. A rate schedule is backdated. On most platforms, that's a manual rebuild — re-run batch jobs, invalidate materialized views, retrigger pipelines, hope you didn't miss a dependency. In GroveStreams, every change — insert, update, or delete — automatically triggers rollup recalculation, derivation recomputation, and dependency propagation up the entire precedent tree. Even historical relationship changes are detected and re-evaluated.
No batch jobs to re-run. No pipelines to retrigger. No manual reconciliation.
Correct the data. The platform does the rest.
Industry Solutions

Rate schedules, meter data, demand profiles, time-of-use billing.

Portfolios, contracts, risk parameters — full temporal history.

Equipment performance, production quality, predictive maintenance.

Patient vitals, device streams, treatment protocol histories.

Fleet location history, shipment telemetry, route performance — position correlated with any stream.

HVAC, energy optimization, occupancy, access control.

Weather, soil, irrigation, yield — independent time axes.
Start Building on the Temporal Intelligence Platform™
90-day full-access trial. No credit card required. From single-stream prototypes to enterprise-scale deployments — 10 years in production.
START FREE TRIAL TRY A DEMO